In this article, I will present the issues related to testing in data projects and introduce one of my tools to address them. In a future article, I will return to the various approaches that can be applied as well as some use cases.
1. The problem of automated testing in data
Testing tools for application development are not necessarily suited for data and BI projects. Indeed, data systems are often chains of complex workflows with multiple dependencies, making it difficult to test the entire process.
In the traditional development world, we are used to the following sequence: CI (build & tests) / deployment / execution. However, for the reasons mentioned earlier, this is not possible in a data project. Instead, we encounter the following sequence: CI (build only) / deployment / execution / tests.

2. Why automate your tests?
- Reduce testing effort: With the industrialization of tests, teams can focus on development or creating complex and high-value test cases.
- Reduce regression risks: By continuously running tests, regressions can be detected quickly and fixed before they impact production.
- Increase test quality: When a new bug is detected, new test cases can be added to the framework to control and prevent a recurrence of the issue, thereby enriching the test base.
- Improve project quality: With fewer regression bugs and a more efficient team on development tasks, the product’s quality improves.
3. Ploosh
What is Ploosh?
Ploosh is a framework that enables quick and simple implementation of tests within data projects. Based on YAML files, it is easily usable by technical teams, but also by business analysts or dedicated testing teams.
However, it’s important to remember that Ploosh is only a toolset, and the intelligence of the tests lies in the people who write them. The documentation is available on the Ploosh wiki.
How it works
Ploosh is based on a simple concept: a test consists of a value to be tested and a reference value. For a test to be valid, the value to be tested must match the reference value.
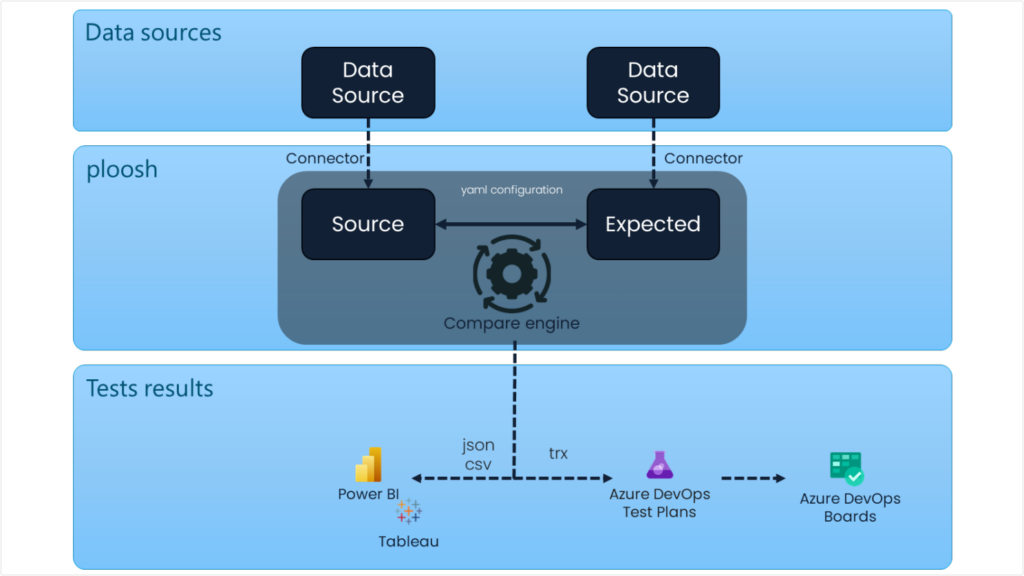
The framework offers three main features forming the test engine:
Connectors: They allow, based on the defined configuration, to query a data source and store the result in a homogeneous format (dataframe), which enables the compare engine to execute.
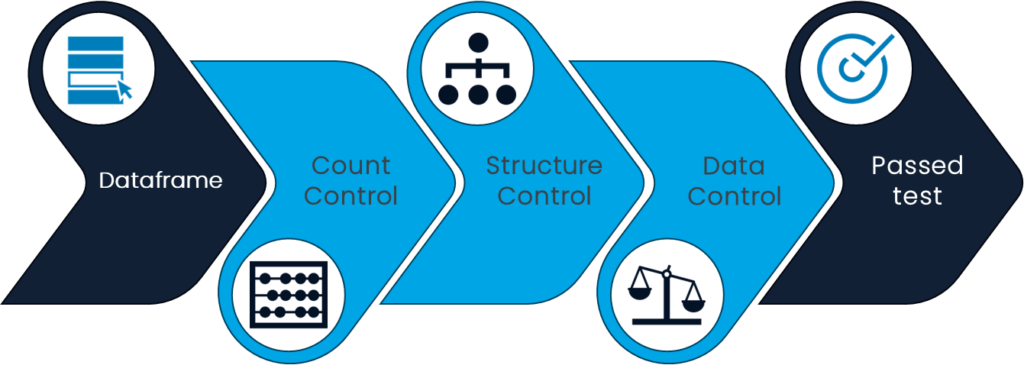
The compare engine: Its goal is to compare, for each test case, the data from the “source” connector configuration with the data from the “expected” connector configuration. It operates in three successive steps:
- Row count comparison between the two datasets.
- Structural equality check between the two datasets.
- Row-by-row data comparison between the datasets to confirm if they match.
Export: This feature allows for leveraging the test results in reports (PowerBI, Tableau, etc.), available in different formats:
- JSON / CSV: Results can be exported as CSV or JSON files, accompanied by an Excel file per test case showing any discrepancies.
- TRX: Results can be exported in the T-Rex format (actually XML with subfolders) and can be used directly in the “Testing Plan” section of Azure DevOps.
4. Exemple
Installing Ploosh is done via the “pip” command. You need to have Python 3.2 or higher installed on your machine or server.
pip install ploosh
Next, we create a connections.yml file to manage the various connections used during the tests. In this example, we create two connections:
dwhsimulates a connection to a data warehouse.dmtsimulates a connection to a datamart. You’ll notice that for the passwords, we use variables. These will be passed via the command line that launches Ploosh.
dwh:
type: mysql
hostname: my_dwh.database.windows.net
database: my_dwh
username: my_user_name
password: $var.my_dwh_password
dmt:
type: mysql
hostname: my_dmt.database.windows.net
database: my_dmt
username: my_user_name
password: $var.my_dmt_password
After this, we create a folder containing our test cases. Inside, we create a file test_cases/demo.yml containing the test cases for this example.
In this case, we will create a test case, “Test users data”, where we verify that the data in the “users” table from the datamart is correctly aggregated by comparing it with the data from the data warehouse.
Test users data:
options:
sort:
- gender
- domain
source:
connection: dwh
type: mysql
query: |
select gender
, right(email, length(email) - position("@" in email)) as domain
, count(*) as count
from users
group by gender, domain
expected:
connection: dmt
type: mysql
query: |
select gender, domain, count
from users
Finally, we execute Ploosh to run the tests:
ploosh --connections "connections.yml" --cases "test_cases" --export "JSON" --my_dwh_password "mypassword" --my_dmt_password "mypassword"
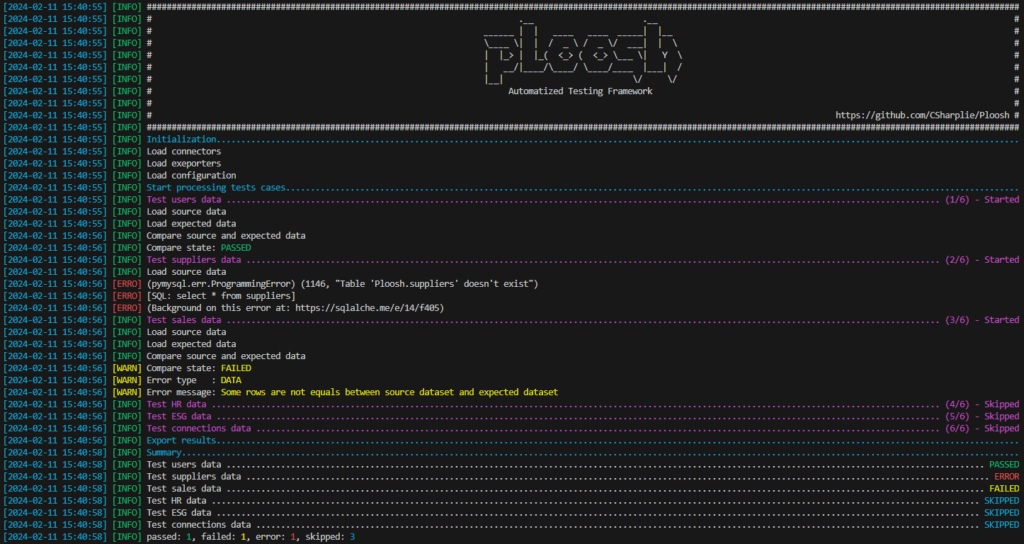
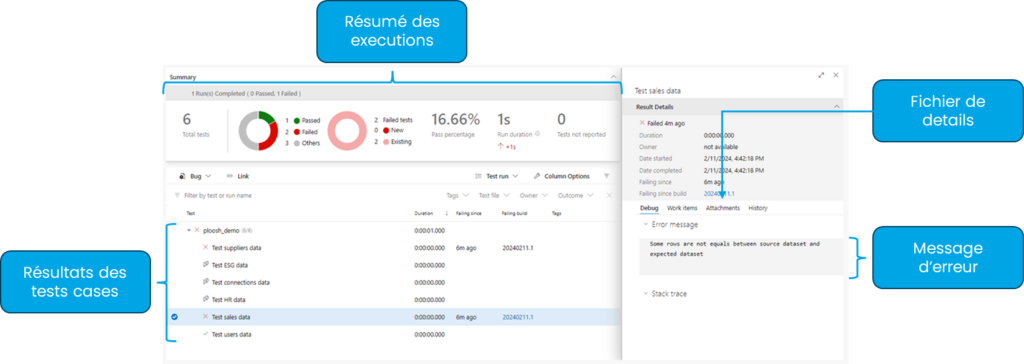
During execution, the status of the tests is displayed in real-time, and a summary will be shown once completed. At the end a file is generated with the details of the tests.
[
{
"name": "Test users data",
"state": "passed",
"source": {
"start": "2024-02-11T15:40:55Z",
"end": "2024-02-11T15:40:55Z",
"duration": 0.003537366666666667
},
"expected": {
"start": "2024-02-11T15:40:55Z",
"end": "2024-02-11T15:40:56Z",
"duration": 0.00014688333333333334
},
"compare": {
"start": "2024-02-11T15:40:56Z",
"end": "2024-02-11T15:40:56Z",
"duration": 0.0010019833333333333
}
},
{
"name": "Test sales data",
"state": "failed",
"source": {
"start": "2024-02-11T15:40:56Z",
"end": "2024-02-11T15:40:56Z",
"duration": 0.0018024166666666666
},
"expected": {
"start": "2024-02-11T15:40:56Z",
"end": "2024-02-11T15:40:56Z",
"duration": 0.0000436666666666666
},
"compare": {
"start": "2024-02-11T15:40:56Z",
"end": "2024-02-11T15:40:56Z",
"duration": 0.00035798333333333335
},
"error": {
"type": "data",
"message": "Some rows are not equals between source dataset and expected dataset"
}
}
]
5. Conclusion
Ploosh est un framework flexible permettant de résoudre les problématiques de tests des projets de données. Il va être amené à être amélioré et à voir ses fonctionnalités augmentées.
Je reviendrai bientôt avec des exemples de cas d’usage, mais aussi avec différentes approches de la mise en place de tests à travers Ploosh.
Ploosh is a flexible framework that solves testing issues in data projects. It is expected to be improved and gain more features. I will come back soon with examples of use cases and different approaches for implementing tests through Ploosh. In the meantime, its source code and wiki are available on GitHub.
See original post on LinkedIn (in french) : Ploosh : un framework pour automatiser les tests en data