In a previous article, I introduced Ploosh, a tool I developed to facilitate testing in the data domain. Today, I will show you a use case where Ploosh was used to improve efficiency during testing phases. This article presents how Ploosh was implemented in a migration project. In a future article, I will demonstrate how it is used in more traditional BI and data projects.
Migration Context
We used Ploosh as part of a cloud migration, a classic use case since we had to manage two heterogeneous data systems: a legacy on-premise system and a target system in SaaS.
Beyond platform and security aspects, when we think of data migration, we generally distinguish between two main areas: data migration and the migration of data feeds. I will elaborate on the second point, although the method can also be applied to data migration.
The scope of the migration included hundreds of processes (or data feeds) handling gigabytes of data across nearly a thousand tables. We used Ploosh to reduce the heavy testing load required to validate the proper functioning of the new data feeds on the target platform.
Testing Strategy
To successfully complete the testing phase, we defined a strategy to cover as many cases as possible while optimizing performance to test a large number of elements.
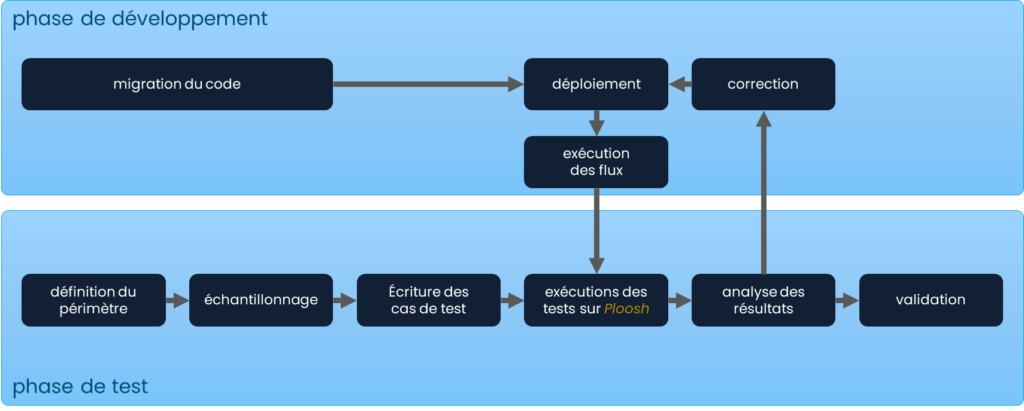
- Code migration: Development of the new processing code ready to be executed on the target environment. The first tests aim to validate the technical functionality. Some basic tests are also carried out at this stage. It is worth noting that the testing phase can begin in parallel with development to optimize the timeline.
- Deployment: Installation of the migrated code on the target environment so it is ready to be executed and tested.
- Defining the testing scope: Identification of the elements to be tested. Most feeds write or update tables. This step identifies the tables impacted by the feed being tested, so the tests can focus on the right elements. This is purely a technical step, based on reading and understanding the code to be migrated.
- Sampling: Defining a representative sample of the data processed by the feed. The idea is to define a sample large enough to cover as many cases as possible, while small enough to ensure the tests are executed in a reasonable amount of time. This step requires a good understanding of the feed to ensure that as many cases as possible are covered. Filters can be very specific (customer IDs, order numbers) or broader (cities, services).
- Writing test cases: Developing the test case with Ploosh. The objective is to create one test case per table to be tested, using the same query and sample to run it on both the legacy and target environments.
- Executing processes: Running the data feeds on both the legacy and target environments to align the two environments in terms of data.
- Running the tests: Executing the test cases to compare the samples from both databases and validate or invalidate the test results.
- Analysis: Analyzing the test case results with Ploosh. If the test case passes, it means the feed produces the same result on the target environment as on the legacy one. Otherwise, the feed is sent back for correction and retested with the same test case.
Sampling Example
As mentioned earlier, sampling is a crucial step in the testing strategy. Two main approaches can be followed:
Precise Sampling
This approach allows for quickly creating test cases by selecting rows using their technical or business keys. Here is a fictitious example with a small sample. In practice, it’s recommended to include a larger number of values to cover more cases
Sales test:
source:
connection: target_connection
type: mysql
query: |
select *
from fact_sales
where sale_id in ('E9EYKDIW6C', 'R5QUFFYXF0', 'FF0YIVG63B', 'DZWG6FJQWO', '7Y8G0EQ3JD', '9PF09Z3A6O', 'P0TIAOVD7D', 'CPY0E0N72T', 'EKCBGJNR25', '06BF63C6C8')
order by sale_id
expected:
connection: legacy_connection
type: bigquery
query: |
select *
from fact_sales
where sale_id in ('E9EYKDIW6C', 'R5QUFFYXF0', 'FF0YIVG63B', 'DZWG6FJQWO', '7Y8G0EQ3JD', '9PF09Z3A6O', 'P0TIAOVD7D', 'CPY0E0N72T', 'EKCBGJNR25', '06BF63C6C8')
order by sale_id -- Always remember to add sorting for easier comparison.
Batch Sampling: This approach is also quick but requires a deeper functional understanding. It involves testing a broader set of data. Here’s an example:
Sales test: source: connection: target_connection type: mysql query: | select * from fact_sales where country = 'france' order by sale_id expected: connection: legacy_connection type: bigquery query: | select * from fact_sales where country = 'france' order by sale_id -- Always remember to add sorting for easier comparison.
Conclusion
Gone are the days of endless Excel comparisons! Using Ploosh allowed us to focus on sampling and migration while testing and retesting our feeds, saving us time and energy. I will be back soon with other concrete examples of use cases and different approaches for setting up tests with Ploosh. In the meantime, you can check out the source code and wiki on GitHub.
See original post on LinkedIn (in french) : Ploosh : comment faciliter ses tests de migration ? | LinkedIn